Voici un tout premier article sur ce petit ordinateur qui vient concurrencer les Arduinos.
La première chose à savoir c’est qu’il existe plusieurs types de RPI nano. Rendez-vous sur le site de Raspberrypi consacré au nano pour les connaître. Y sont présentés les quatres modèles de la famille : Raspberry Pi Pico, Pico H, Pico W et Pico WH.
Les différences sont les suivantes :
le Pi Pico n’a pas de pattes GPIO présoudées et son connecteur SWD (Serial Wire Debug) est composé de trois petits trous à l’opposé du connecteur mini USB,
le Pi Pico H a des pattes GPIO présoudées et son connecteur SWD (Serial Wire Debug) est un petit connecteur à trois broches mâles,
le Pi Pico W n’a pas de pattes GPIO présoudées, son connecteur SWD (Serial Wire Debug) est composé de trois petits trous au milieu de la carte et il dispose du Wifi et du bluetooth et
le Pi Pico WH a des pattes GPIO présoudées, son connecteur SWD (Serial Wire Debug) est un petit connecteur à trois broches mâles et il dispose du Wifo et du bluetooth.
Pour commencer, nous allons utiliser un Pi Pico sans broches. Pour le mettre en oeuvre deux choses sont nécessaires : un câble USB-microUSB et le logiciel Thonny. Le premier permettra de relier le nano à votre RPI4, par exemple, et le second permettra d’y envoyer des instructions en python.
Les RPI pico étant des ordinateurs qu’on peut programmer avec différents langages, il faut avant toute chose mettre sur le RPI pico le logiciel (firmware) qui va comprendre le python.
Installation du firmware
Pour cela, nous allons monter le RPI pico comme une clé USB et y déposer le firmware. Pour cela, le pico dispose d’un petit bouton très visible sur le dessus de la carte. En maintenant pressé celui-ci connectez le pico à votre RPI4 via le câble USB. Cela fait, attendez trois secondes et relâchez celui-ci. Votre pico devrait apparaître sous la forme d’une clé USB.
Deux fichiers se trouveront dans votre pico : INDEX.HTM et INFO_UF2.-txt. Le premier est un lien vers le site du Raspberrypi consacré au pico et le second contient des informations sur le firmware déjà installé. Par exemple :
UF2 Bootloader v2.0
Model: Raspberry Pi RP2
Board-ID: RPI-RP2
Pour installer le bon firmware, rendez-vous à la page permettant de télécharger le firmware du nano. Téléchargez-y le firmware, d’extension uf2, pour votre nano et copiez-le par « drag and drop » dans le navigateur de fichier ouvert sur votre nano. Normalement, après quelques secondes votre nano devrait disparaître. Vous verrez un message d’alerte spécifiant qu’un disque a été éjecté sans être démonté. C’est normal. Vous avez « flashé » le firmware sur votre nano. Retirez le câble USB et remettez-le.
Hello world
Votre nano est maintenant prêt pour être programmé. Pour ce faire, lancez « Thonny ». Cela fait, il présentera en bas à droite le petit texte : Local Python 3 /usr/bin/python3. Cliquez dessus et vous verrez apparaître : MicroPython (Raspberry Pi Pico) /dev/ttyACM0. C’est votre pico. Cliquez dessus. La console de Thonny devrait se remplir de texte et mettre l’invite de commande python : >>>.
Dans la partie supérieure de Thonny, en-dessous du <untiteld>, composez l’instruction :
print('Bonjour Monde')
et appuyez sur le bouton vert rond avec un triangle à l’intérieur pour que le programme soit lancé. Vous verrez alors apparaître le texte « Bonjour Monde » dans la console. Tout fonctionne bien.
À ce stade, vous pouvez enregistrer ce petit programme dans un fichier de nom « helloworld.py », par exemple (le .py est obligatoire et le nom du fichier ne doit pas comporter d’espaces ou de caractères particulier).
Attention cependant, la mémoire du raspberrypi nano étant de 1,375 Mo, votre code ne doit pas dépasser 1’441’792 octets (données du système de fichier comprises).
Enfin, sachez que pour que le nano lance un programme sans être branché sur un autre ordinateur, alimenté par un powerbank, par exemple, il faut que le nom du fichier à lancer soit : main.py.
Voilà pour ces premiers pas avec un Raspberrypi nano.
Un livret est un document réalisé dans un format donné, A4 par exemple, mais imprimé sur des feuilles de format supérieur (A3, pour un document A4, par exemple) pour permettre d’utiliser la feuille elle-même comme reliure. On imprime donc deux pages sur un feuille et on la plie.
Le problème est que pour pouvoir réaliser un document de plus de deux pages, il faut faire bien attention à ce qu’on va imprimer au verso de la feuille. Par exemple, pour un document de quatre pages, la page quatre doit se trouver au dos de la page un et la page trois au dos de la deux. De plus, elles doivent être dans le bons sens, c’est-à-dire qu’il ne faut pas qu’on doive retourner la feuille à chaque fois qu’on tourne la page. Vous ne rirez pas bien longtemps si vous ne comprenez pas le problème. Placer les pages aux bons endroits constitue une imposition. Celle-ci peut être très complexe suivant le nombre de page que vous voulez placer sur la feuille (voir Wikipedia).
Pour réaliser un livret, il faut donc un logiciel permettant d’imprimer plusieurs pages sur une seule et de les imposer correctement.
Cet article va se limiter au cas de la création d’un livret A4 sur des feuilles A3 et va présenter deux logiciels permettant de réaliser cette opération : LibreOffice et Pdfjam. Le premier s’utilise dans une interface graphique et le second en ligne de commande.
LibreOffice
Il est naturel que la production du document soit réalisée avec les réglages correspondants à la taille des pages du document final, soit ici A4. On réalise donc celui-ci en paramétrant le logiciel pour qu’il utilise le format A4. Avec LibreOffice, le réglage de la taille de la page se fait au moment de l’impression Cela laisse penser que LibreOffice va automatiquement adapter le contenu mis en forme aux exigences du format papier choisi, ce qui n’est pas le cas. En réalité donc, il vaut mieux le spécifier dès le départ et choisir le format A4 en mode portrait. La logique l’impose aussi.
Une fois le document réalisé en A4, il est très facile de produire le livret. Il faut aller dans le menu d’impression et dans « Plus d’options » sélectionner « Brochure ». Normalement, l’aperçu avant impression devrait alors montrer la feuille A3 en mode paysage sur laquelle se trouvent les pages A4 en mode portrait. Si ce n’est pas le cas, il faut aller dans les « Propriétés… » de l’imprimante et sous l’onglet « Papier » cocher « Utiliser uniquement … » en choisissant le format A3 paysage. Alors, l’impression sur papier ou PDF se fera correctement. Enfin, presque, car le verso des feuilles A3 sera orienté de la même manière que le recto. En d’autres termes, le pied de page sera des deux côtés sur le même long côté de la feuille. Or, certaines imprimantes produisent le verso dans le sens contraire du recto et il peut être nécessaire de produire un PDF avec les pages inversées.
LibreOffice ne permet pas cela.
Pour s’en sortir, il faudra alors imprimer un PDF comprenant uniquement les pages paires et un autre avec uniquement les pages impaires. Puis, il suffira d’imprimer le premier, de remettre les feuilles ainsi imprimées dans l’imprimante et d’imprimer le second.
Pdfjam
The package makes available the pdfjam shell script that provides a simple interface to much of the functionality of the excellent pdfpages package (by Andreas Matthias) for LaTeX. The pdfjam script takes one or more PDF files (and/or JPG/PNG graphics files) as input, and produces one or more PDF files as output. It is useful for joining files together, selecting pages, reducing several source pages onto one output page, etc., etc.
Pdfjam est donc installé avec Texlive, l’excellente distribution LaTeX. Si celle-ci est installée, vous disposez déjà de pdfjam et il vous suffit de faire un « man pdfjam » dans une console pour disposer de son manuel.
Ici nous allons l’utiliser en une seule ligne de commande. Préalablement, il faut vous rendre dans le répertoire dans lequel se trouve le fichier pdf A4 que vous voulez produire sous la forme d’un livret A3. Ce fichier comprend simplement toutes les pages A4 de votre document dans l’ordre de la pagination.
Cette commande appelle pdfjam et demande une sortie sous la forme d’un livret (book) en mode paysage (landscape) et de format A3. Les options trim et clip retirent 1cm tout autour du pdf de façon à ce que les marges prévues par l’imprimante n’aient pas trop d’importance. Faite cependant des essais pour que la sortie soit le mieux adaptée à ce que vous désirez (voir le manuel du package Pdfpages ou la discussion How to properly put two pages onto one using pdfjam?). La signature quant-à-elle est un nombre représentant le premier nombre divisible par quatre après le nombre de pages du document. Ainsi, si votre document fait 77, 78 ou 79 pages, la signature sera 80. Enfin, vient le nom du PDF de sortie suivi d’un tiret.
L’utilisation d’un tableur en ligne de commande s’est avérée nécessaire pour moi tant par philosophie que parce que, n’utilisant plus libre office que pour son tableur, j’ai trouvé regrettable d’installer autant de choses que pour cela. Bien entendu Gnumeric pouvait faire l’affaire, mais le plaisir que j’éprouve aujourd’hui à utiliser la ligne de commande m’a poussé à aller plus loin en cherchant un tableur en ligne de commande.
Trois tableur se sont alors présentés à moi : Oleo, sc-im et sc. Les deux premiers n’étant pas dans les dépôt de Raspberrypi OS (ni de debian d’ailleurs), je me suis d’abord intéressé à sc, le plus ancien tableur en ligne de commande.
Le vénérable tableur sc
Installation
Son installation s’est donc faite sans aucun problèmes par :
apt install sc
Utilisation
Le lancer fut tout aussi facile :
$ sc
et vous vous retrouvez devant un beau tableur :
Sc avec quelques données
Les difficultés commencent alors. Ce sont des difficultés classiques liés à la manipulation d’un objet complexe au clavier.
On voit à la figure précédente, tout en haut à gauche, une ligne d’information :
la cellule sélectionnés (A0, en blanc dans le tableur)
suivie de trois chiffres entre parenthèse (10 0 0) qui correspondent respectivement à la taille de la cellule (10), au nombre de chiffres après la virgule (ici un entier, soit 0) et au format de nombre (0 pour une représentation décimale, 1 pour une représentation scientifique, 2 pour une représentation d’ingénieur et 3 pour les dates) et
le contenu de la cellule entre crochets (ici vide [ ]).
Insertion
Le mode d’insertion de données est obtenu en fonction du type de données à insérer :
données numériques : dans le mode décrit ci-dessus (A0 (10 0 0) [ ] visible), il faut entrer le signe d’égalité. Le informations A0 (10 0 0) [ ] disparaissent alors et sont remplacées par la commande : let A1 = On peut alors y placer le nombre souhaité et valider l’entrée pas la touche <Enter>. Le nombre apparaîtra alors entre les crochets de la ligne d’information.
données textuelles : toujours dans le mode présentant la ligne d’information et suivant le format d’alignement dans la cellule (aligné à gauche, centré, aligné à droite), on peut utiliser :
< pour faire apparaître la commande : leftstring A1 = » permettant l’insertion d’une chaîne de caractères justifiée à gauche après l’ouverture des « ,
\ pour faire apparaître la commande : label A1 = » permettant l’insertion d’une chaine de caractères centrés après l’ouverture des « ,
> pour faire apparaître la commande : rightstring A1 = » permettant l’insertion d’une chaîne de caractères justifiée à droite après l’ouverture des « .
On comprend rapidement qu’il suffit de savoir ce qu’on veut faire pour pouvoir le faire directement dans la ligne d’insertion :
i> label A1 = "
On peut évidemment effacer label A1 = » et le remplacer par exemple par leftstring A3 = « . L’important est de se trouver dans le mode d’insertion (i>). Pour cela, il suffit de presser la touche <Enter>.
Pour annuler l’insertion d’une commande, c’est-à-dire revenir à la ligne d’information, il suffit soit de valider la commande en pressant <Enter>, soit de l’effacer et de presser <Enter>.
Pour effacer une donnée, il suffit d’appuyer sur la touche <x>, comme avec vi.
Automatisation des calculs
L’une des fonctionnalités parmi les plus importante des tableurs tient dans les calculs réalisable à partir de différentes cellules et à l’automatisation de ceux-ci par recopié vers le bas. Comment cela fonctionne-t-il avec sc ?
Évidemment, l’écriture d’équations est fonctionnelle en mode insertion :
i> let A1 = A7 + 2
par exemple. À tout moment on peut en mode insertion définir le contenu d’une cellule quelconque.
Ensuite, pour effectuer un recopié vers le bas, il faut d’abord presser la touche <c> suivit du point <.> pour copier (c) la formule de la cellule courante (.). Un « Copy marked cell » apparaît. Ensuite, le tableur passe automatiquement en mode copie (v> copy [dest_range scr_range]) et on peut sélectionner les cellules en se déplaçant avec les flèches du clavier. Le tableur reporte : « Default range : B4:B25 », par exemple. Enfin, pour effectuer les calculs, il faut valider à l’aide de la touche <Enter>.
Problèmes
Bien d’autres possibilités sont offertes par sc, comme un export en table LaTeX. Mais, je ne les documenterai pas ici, car sc présente des problèmes d’import de données si importants que, malgré la nécessité de compiler sc-im, c’est vers celui-ci que je me suis finalement définitivement tourné.
Avec sc, il n’existe pas nativement la possibilité d’utiliser le press-papier, ni celle d’importer des fichiers csv, ni même celle d’importer des fichiers ods, par exemple. C’est extrêmement ennuyeux et, même si des solutions sont proposées ci et là, comme celle d’un script python de conversion d’un fichier csv en un fichier sc, c’est finalement peu pratique à utiliser.
De plus, sc-im se trouve utiliser une syntaxe bien plus proche de vim que sc et il existe avec lui un mode visual comme avec vim qui permet des sélections très intéressantes. Tout cela entre autre choses.
Tournons-nous donc maintenant vers sc-im.
Le nouveau tableur sc-im
Installation
Sc-im n’est pas dans les dépôts ni de Raspberrypi OS, ni de Debian. Il est donc nécessaire de le compiler. Pour cela, au préalable, il faut avoir installé les librairies nécessaires. Selon la page du projet, il s’agit de :
ncurses (best if compiled with wide chars support)
bison or yacc
gcc
make
pkg-config and which (for make to do its job)
tmux / xclip / pbpaste (for clipboard copy/paste)
gnuplot (for plots)
Or, la compilation sous Raspberrypi ou Debian est quelque peu différente. Elle est très bien décrite sur la page dédiée du site du projet. En suivant les instructions, sans pour Raspberrypi OS réaliser les dernières opérations :
c’est-à-dire en laissant la première ligne, mais en omettant pas de réaliser la dernière après make et make install :
stow --dir=/usr/local/stow sc-im
la compilation se réalise aisément et on peut finalement lancer sc-im en l’invoquant simplement.
Utilisation
Sc-im ouvre les fichier réalisés avec sc. Mais, les formules ne sont pas importés, seul le contenu textuel est numérique l’est.
Une partie des commandes clavier de sc sont encore utilisables avec sc-im. Mais les changements liés au mode de fonctionnement sont à souligner. Voici son interface :
L’interface du tableur sc-im
Plusieurs choses sont à souligner. La première ligne comprend le nom du fichier, suivi de {Sheet1}. Cela pourrait supposer qu’il existe une gestion des feuilles de calcul. Mais, je n’ai pas trouvé de la documentation à ce propos. Tout à gauche se trouve entre — le mode de fonctionnement actuel du tableur. Ici : — NORMAL –.
Modes de fonctionnement
Il faut savoir qu’il existe plusieurs mode de fonctionnement :
Normal : c’est le mode permettant de se déplacer dans le tableur et d’entrer des commandes générales, comme = pour insérer un contenu numérique.
Insertion : c’est le mode permettant d’insérer des données dans les cellules. Pour y accéder, plusieurs touches sont disponibles : = pour insérer une donnée numérique ou une formule, < pour insérer un texte justifié à gauche, \ pour insérer un texte centré et > pour insérer un texte justifié à droite. C’est le même fonctionnement que sc.
Édition : c’est le mode permettant d’éditer le contenu d’une cellule. Il est accessible avec la touche <e> pour éditer un contenu numérique et la touche <E> pour un contenu textuel. Une fois dans le mode d’édition, les commandes vim sont accessibles, comme par exemple la touche <i> pour insérer dans le texte, …
Commande : c’est le mode permettant d’insérer des commandes spéciales comme enregistrer le fichier. Il est accessible avec la touche < : >. Par exemple, on peut écrire :x pour enregistrer et quitter sc-im simultanément ou : w monficher.sc pour enregistrer le contenu du tableur dans le fichier monfichier.sc.
Visuel : c’est le mode permettant de sélectionner simplement plusieurs cellules simultanément pour leur appliquer une action d’un seul coup. Pour l’activer, il faut utiliser la touche <v>, puis utiliser les flèches de déplacement.
La première commande à connaître est :h ou :help, qui va vous permettre d’accéder à l’aide directement dans le tableur. Celle-ci est très complète.
Je me limiterai ensuite au commandes les plus utiles de mon point de vue.
Formatage
En mode normal, par exemple, taper directement < { > permet d’aligner un contenu textuel à gauche, < | > permet de l’aligner au centre et < } > permet de l’aligner à droite. De la même manière, en sélectionnant des cellules en mode visuel par exemple et en utilisant l’une ou l’autre des touches < | >, < { > ou < } >, on formate celles-ci en conséquence. La touche <x> permet d’effacer le contenu d’une cellule ou celui de cellules précédemment sélectionnées. Comme avec vim, utiliser deux fois <y>, soit yy, permet de copier le contenu d’une cellule qu’on peut coller dans une autre avec <p>. En tapant la touche <f>, puis <->, on diminue le nombre de décimales et on l’augmente par <f>, suivie de <+>. Avec <f> suivie des flèches droite ou gauche, on diminue ou augmente la taille de la cellule.
Copié vers le bas
De même, pour effectuer un copier vers le bas, il suffit de copier une formule avec <yy>, passer en mode visuel avec <v>, de sélectionner les cellules dans lesquelles on veut copier la formule et de presser <P>. Si le contenu est numérique ou textuel, il est simplement copié vers le bas. S’il s’agit d’une formule, elle sera recopiée vers le bas avec un changement consécutif des numéros de lignes. De même si on recopie à gauche ou a droite. Ce comportement est bien plus simple que celui de sc. La commande :fcopy permet aussi de copier vers le bas. Voir le manuel.
Manipulation de lignes ou colonnes
Des commandes relatives aux lignes et aux colonnes sont aussi disponibles. Par exemple :
dr ou dc (delete row ou delete column) permettent de supprimer une ligne, respectivement une colonne,
ir ou ic (insert row ou insert column) permettent d’insérer une ligne, respectivement une colonne avant la ligne ou colonne en cours,
oc ou or (open row ou open column) permettent d’insérer une ligne, respectivement un colonne après la ligne ou column en cours,
yr ou yc (yank row ou yank column) permettent de copier une ligne, respectivement une colonne et
p permet de coller une colonne précédemment copiée qui viendra se placer avant la colonne courante.
Déplacements de cellules
Il est aussi possible de déplacer (s : slice) des cellules sélectionnées :
sk, sj, sh, sl permettent de déplacer une cellule ou un ensemble de cellule sélectionnés respectivement en haut (k), en bas (j), à gauche (h) et à droite (l).
Tri de données
Des possibilités de tri existent dont voici un exemple :
:sort C2:E143 "+$C;+$D"
Cela signifie qu’un tri de la plage de données C2 à E143 doit être effectué sur la base des deux critères donnés entre guillemets : +$C signifie un tri croissant (+) de données alphanumériques ($) selon la colonne C, puis (c’est-à-dire ensuite) +$D un tri alphanumérique selon la colonne D. On peut penser à des noms (colonne C), prénoms (colonne D) et la classe (colonne E). Pour un tri de données numériques, à la place du $, il faudrait utiliser un #.
Annulation
Chaque pression sur la touche < u > permet d’annuler successivement chaque opération réalisée.
Export
Signalons qu’il est possible d’exporter le tableau directement en LaTeX par la simple commande :
:e tex
ou, si le ficher tex existe déjà :
:e! tex
comme il est possible d’exporter en csv avec :
:e csv monfichier.csv
D’autres formats d’exports sont disponibles.
Import
Pour importer un fichier, il suffit de lancer sc-im avec son nom. Par exemple :
sc-im monfichier.csv
Presspapier
Relevons enfin que le press-papier est utilisable avec les commandes :
:ccopy et cpaste
mais que pour en disposer, il faut installer le paquet « xclip ». Ainsi, pour transférer des données en colonnes de Gnumeric par exemple dans sc-im, il suffit de les sélectionner, de les copier et, dans sc-im, de se placer dans la première case qui doit les accueillir et de taper :cpaste pour les voir remplir les cases sous-jascentes de la colonne. Malheureusement, si on sélectionne plusieurs colones, lors du collé dans sc-im, les données de chaque colonnes vont être fusionnées dans une seule. Il faut donc procéder colonne après colonne. Voir aussi le manuel.
Avec l’article 19. Calendrier en ligne de commande, nous avons vu comment utiliser un calendrier en ligne de commande avec « calendar-cli ». Dans le présent article, nous allons voir un outil plus pratique et plus puissant pour gérer les calendriers :
khal, couplé avec vdirsyncer
Il s’agit d’outils permettant de gérer (khal) et synchroniser (vdirsyncer) des calendriers locaux et distants.
Installation
Autant vdirsyncer que khal sont présents dans les dépôt de Debian ou Raspberry Pi OS, tant 32 que 64 bits. Il suffit donc d’un :
apt install khal vdirsyncer
en root ou avec sudo.
Configuration
Les deux outils nécessitent une configuration. Pour cela, trois répertoires sont nécessaires :
~/.config/khal
~/.config/vdirsyncer
~/calendriers
Dans le premier doit se trouver le fichier de configuration pour khal : config. Dans le second, doit se trouver le fichier de configuration pour vdirsyncer : config et dans le dernier vont se trouver les calendriers eux-même.
Vdirsyncer
Commençons par la configuration de vdirsyncer.
[general]
status_path = "~/.vdirsyncer/status/"
[pair my_calendars]
a = "professionnel_local"
b = "professionnel_distant"
collections = ["from a", "from b"]
[storage prof_local]
type = "filesystem"
path = "~/.calendriers/"
fileext = ".ics"
[storage prof_distant]
type = "caldav"
url = "https://lurl_avec_tous_les_calendriers/"
username = "machin"
password.fetch = ["prompt", "Mot de passe pour le calendrier"]
On voit qu’on définit un calendrier local et un distant de type .ics et caldav, respectivement. Le mot de passe sera demandé à chaque synchronisation.
khal
Ensuite, la configuration de Khal se fait ainsi :
[calendars]
[[professionnel]]
path = ~/.calendriers/professional/
color = light magenta
[[personnel]]
path = ~/.calendriers/personal/
color = light green
[[anniversaires]]
path = ~/.calendriers/contact_birthdays
color = light red
[locale]
timeformat = %H:%M
dateformat = %d/%m/%Y
longdateformat = %d/%m/%Y
datetimeformat = %d/%m/%Y %H:%M
longdatetimeformat = %d/%m/%Y %H:%M
Khal va utiliser les calendriers découverts par vdirsyncer et placés dans les répertoires qui se trouvent sous « ~/.calendrier/ ». Dans ceux-ci se trouvent les fichiers .ics contenant les événements.
Première synchronisation
Pour découvrir et rapatrier les calendriers et leurs événements, il faut le demander à vsyncer par la commande :
vdirsyncer discover
Après la découverte des calendriers, il faut les synchroniser avec :
vdirsyncer sync
Alors seulement Khal va vous permettre de les manipuler.
Utilisation
Dès lors, vous pouvez lancer la commande :
khal interactive
qui vous permettra de visualiser et manipuler vos événements. Voir la figure ci-dessous.
Khal interactive
Khal interactive est très puissant, puisqu’en pressant la touche <n>, pour nouveau, on peut ajouter un événement à l’un ou l’autre des calendriers, y définir un alarme ou d’autres propriétés que je vous laisse découvrir. La touche <?> vous en dira plus.
Pour une description des autres possibilités de ce logiciel, il suffit de taper khal dans la ligne de commande.
Attention, la synchronisation avec le calendrier distant n’est pas automatiques. Il faut, après chaque modifications, relancer la commande :
La question est : pourquoi augmenter le nombre de bits. On va voir ici que cette augmentation permet une gestion de la transparence.
Pour commencer, à l’instar de l’article précédemment cité, commençons par créer un fichier BMP à l’aide de GIMP. Il s’agit d’un fichier de 5 x 5 pixels, remplis de couleurs à l’aide du crayon de Gimp. Il a l’allure suivante :
L’image réalisée avec Gimp (5 x 5 pixels)
Soulignons bien la taille de l’image (5 x 5 pixels). Celle-ci est ensuite exportée au format bmp avec pour réglages spécifiques (à préciser au moment de l’exportation) :
Exportation en 32 bits
Relevons que le choix du mode A8 R8 G8 B8 ne peut se faire que si un canal alpha a été ajouté via le menu « Calque » puis « Transparence ». En effet, A8 signifie que huit bit, soit un octet, va être ajouté pour le canal alpha (A), alors qu’avec X8, huit bits d’une valeur nulle sont ajoutés.
Analyse
Une fois le fichier créé, analysons-le par comparaison avec la description du format de fichier en 24 bits :
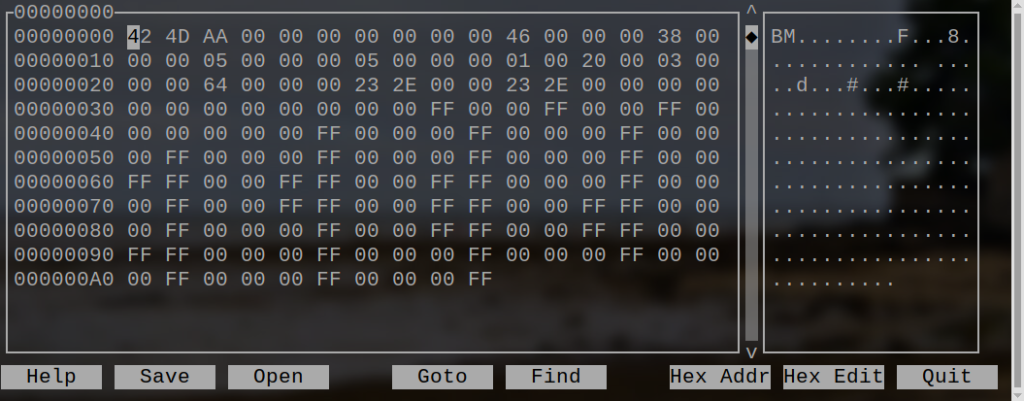
et à l’aide d’Hexcurse :
hexcurse RougeNoir.bmp
On obtient ainsi :
Le fichier BMP en 32 bits
À part les deux premiers octets du BM, on note une taille totale du fichier de 170 octets (AA), un offset de l’image à 70 octets (46) et une taille de l’entête de 56 octets (38). La taille de la partie fichier est donc de70 – 56 = 14 octets, comme en 24 bits.
Sur la seconde ligne, la taille de l’image est donnée 05 et 05 et le nombre de plans utilisés (1), à l’instar du 24 bits. Ensuite, à la place de 18, le nombre de bits par pixel est spécifié : 20, soit 32 en décimal. Ces huit bits en plus constituent un octet supplémentaire. On aura donc non pas trois octets représenté par trois groupes de deux nombres hexadécimal, mais quatre.
La taille de l’image est ensuite précisée par 64, soit en décimal 100 octets, ce qui est en accord avec l’offset de celle-ci et la taille de l’image.
Viennent ensuite les résolutions horizontales et verticales à 2E23, soit en décimal, 11811 pixels par mètre, soit à 2,54 cm par pouce 11’811·0,0254 = 300 dpi.
L’image
Analysons maintenant l’image elle-même. L’offset de celle-ci est à 46 en hexadécimal, elle est composée de lignes de 5 pixels comprenant 4 octet chacun, soit au total 20 octets. Or, 20 est divisible par 4. Il n’y a donc pas d’octet supplémentaire. Nous allons donc demander des lignes de 20 octets (-c 10), groupés par 4 (-g 4) et commençant à 46 :
xxd -g 4 -s 46 -c 20 RougeNoir.bmp
Le résultat est le suivant :
L’image en 32 bits, soit sur 4 octets
On voit tout d’abord que les 25 pixels sont présent sous la forme de groupes de 4 octets ou huit chiffres hexadécimaux. Il n’y a donc bien pas d’octets supplémentaires fictifs. On voit aussi que tous les pixels se terminent par FF. La structure des 4 octets est la suivante : BVRA, soit l’inverse de la dénomination A8 R8 V8 B8. Ainsi, le dernier octet toujours à FF signifie qu’aucun octet n’est transparent. Nous y reviendrons.
Pour les 3 octets le précédant, on voit bien un contour noir (000000ff) et un cœur rouge (0000ffff). Ce qui est conforme à l’image créée sous Gimp.
Transparence
Le dernier octet est donc un octet de transparence avec FF signifiant aucune transparence et 00 une transparence totale. Nous allons l’illustrer en changeant la transparence des 9 pixels rouges centraux à l’aide d’hexcurse. On va donc changer le dernier octet de chaque pixel de la manière suivante : en haut à droite on commence par 25 (19 en hexadécimal), puis en allant vers la gauche 50 (32) et 75 (4B). Ensuite, on descend et repart de la gauche avec 100 (64), 125 (7D) et 150 (96), on descend et repart vers la gauche avec 175 (AF), 200 (C8) et 225 (E1). Le fichier correspondant est :
Un « dégradé » de transparence
Le changement des octets se fait simplement en plaçant le curseur sur un chiffre et en le remplaçant pas un autre. Ensuite, on enregistre par <ctrl – s> et on rouvre le fichier sous Gimp. Voici le résultat :
La transparence
Conclusion
L’édition en 32 bits d’un fichier BMP nous a permis de comprendre comment est codée la transparence. C’est plutôt simple.
Reste peut-être qu’un détail ne vous aura pas échappé : un petit octet à 03 dont je vous laisse trouver l’explication.
Le format d’image BMP est intéressant car il constitue un exemple simple de format hexadécimal documenté. Une image BMP (c’est-à-dire d’extension .bmb) est en effet constituée d’octets qu’il est possible d’analyser avec un éditeur hexadécimal comme hexcurse ou xxd et obéit à la structure suivante :
Structure d’un image BMP
Pour nous familiariser avec cette structure nous allons créer avec Gimp une image très simple de taille 5 x 5 pixels au format bmp. Lancez donc Gimp, puis choisissez « Nouvelle image » dans le menu « Fichier ». Dans la boite de dialogue qui s’ouvre, choisissez pour la taille de l’image une largeur et une hauteur de 5 pixels et validez. Votre image sera très petite. Utilisez la loupe pour l’agrandir.
Choisissez alors le crayon et dans ses options de configuration qui s’offrent à vous en le choisissant, mettez sa taille à 1 (pixel). Choisissez ensuite dans le sélecteur de couleur (deux carrés superposés) les différentes couleurs nécessaires pour obtenir l’image suivante :
L’image à créer sans la bordure grise.
Attention, cette image ne doit être constituée que de 25 pixels (5 x 5 pixels).
Enregistrez alors via « Exporter » du menu « Fichier » en nommant l’image image.bmp et en validant par « Exporter ». Une nouvelle boite de dialogue apparaîtra alors avec deux menus déroulants nommés « Options de compatibilité » et « Options avancées ». Dans le premier cochez « Ne pas inscrire l’information de couleur » et dans le second choisissez une représentation des pixels sur 24 bits : R8G8B8. Exportez sur votre bureau par exemple et fermez Gimp.
Vous avez maintenant un fichier BMP (bitmap) dont la structure correspond celle présentés ci-dessus. Pour s’en rendre compte, nous allons l’ouvrir avec un éditeur hexadécimal.
Commençons par utiliser Hexcurse. Placez-vous sur le bureau et lancez la commande :
hexcurse image.bmp
Le résultat sera le suivant :
Le fichier image.bmp en hexadécimal
On peut analyser la structure de ce fichier avec cette image. Mais, il est plus pratique de le scinder selon chacune des trois parties présentées dans la structure ci-dessus, à savoir : fichier, entêtes images et image.
Rappelons avant de les présenter qu’un octet correspond à huit chiffres binaires 0 ou 1. Ainsi, le nombre 01001100 est un octet. Sa traduction en décimal vaut 76 et celle en hexadécimal 4C. On peut comprendre, par le fait que le nombre de nombres binaires réalisables à l’aide d’un octet est de 2^8 = 256 et que celui de nombres hexadécimaux réalisables à l’aide de deux chiffres hexadécimaux (de 0 à F) est de 16×16 = 256, qu’à chaque nombre binaire codé sur un octet, correspond un nombre hexadécimal codé sur deux chiffres. Ainsi à un ensemble de deux chiffres hexadécimaux correspond un octet.
Partie fichier
Commençons par la partie fichier. Il s’agit d’afficher les 14 premiers octets. Avec xxd, cela se fait ainsi :
xxd -g 1 -l 0x0E -c 4 image.bmp
L’option -g 1 permet de séparer les octets un à un par un espace. L’option -c 4 permet d’afficher les octet sur quatre colonnes et l’option -l 0x0E permet de n’afficher que les 14 premiers octets. En effet, 0E en hexadécimal vaut 14 en décimal.
Le résultat est le suivant :
La partie fichier
On y voit trois éléments, à gauche le numéro du dernier octet de la ligne précédente, au milieu la partie ficher de l’image et à droite une tentative de conversion des octets sous forme textuelle. C’est la partie centrale qui nous intéresse.
Les deux premiers octets sont correctement traduit sous forme textuelle par les caractères B et M pour BitMap. Elle permet d’identifier le type de fichier.
Les quatre octets suivants représentent la taille du fichier. Ici 86 en hexadécimal correspond à 134 en décimal. La totalité du fichier contient donc 134 octets. Or, 134 octets = 134/1024 = 0,1309 ko. C’est précisément que qu’affichent les propriétés du fichier. Notez, comme on le verra plus loin pour la résolution de l’image que les quatre octets se lisent à l’envers. Ainsi, si la taille de l’image était notée : 86 1A 00 00, il faudrait lire le nombre hexadécimal 1A86.
Les quatre octets suivants sont réservé et posés nuls.
Enfin, les quatre derniers octets précisent la position de l’image qui commence ici juste après le 54e octet (36 en hexadécimal).
Partie entêtes image
L’entête de l’image correspond aux octets après le 14e, jusqu’au 54e, soit 40 octets au total, 28 en hexadécimal, en hexadécimal de 0E à 36. On peut donc écrire la commande permettant de l’afficher ainsi :
xxd -g 1 -s 0x0E -l 0x28 -c 4 image.bmp
L’option -l permet de spécifier le nombre d’octets qu’on désire après celui spécifié par -s. Le résultat est le suivant :
Entêtes de l’image
La première ligne, dont le premier octet à 28, soit 40 en décimal, nous donne la taille des entêtes qu’on peut aussi obtenir ici par le fait que 10 lignes de 4 octets sont présentes, soit au total 40 octets.
Les deux lignes suivantes donnent respectivement la largeur et la hauteur en pixels de l’image. Ici, on a une image de 5 (en hexadécimal, soit aussi 5 en décimal) par 5 pixels, ce qui est conforme à la taille de l’image créée avec Gimp.
On voit ensuite le nombre de plans utilisés, codé sur deux octets, ici 1 plan, et le nombre de bits par pixel, ici en hexadécimal 18, soit 24 bits par pixel en décimal, aussi codé sur deux octets. Il s’agit donc d’une image en vraie couleurs, codée sur 24 bits, soit 8 bits par couleur ou 1 octet par couleur. On en déduit que trois groupes de deux chiffres hexadécimaux permettrons dans l’image de représenter la couleur d’un pixel. Ce nombre représente le choix fait lors de la création du fichier bitmap d’une représentation sur 24 bits notés R8G8B8.
Suit la méthode de compression sur 4 octets, ici aucune.
Puis viens la taille de l’image sur 4 octets, ici de 50, soit en décimal 80 octets. La vérification semble simple. En effet, une image de 5 x 5 pixels contient 25 pixels. Avec trois octets par pixel, on a donc 25 x 3 = 75 octets. Il manque donc 5 octets. Où sont ils passés ?
La dernière ligne de la spécification du format de l’image dit que chaque ligne doit comporter un nombre d’octets qui soit un multiple de 4. Comme on a des lignes de 5 pixels, le nombre d’octets par ligne nécessaires pour l’image vaut 15, puisque trois octets sont nécessaire par pixel. Or, 15 n’est pas un multiple de 4. Il faut donc 16 octets par ligne, soit ici, mais cela peut être plus dans d’autres cas, un octet supplémentaire par ligne. Il faut donc ajouter à l’image 5 octets. On passe alors de 75 à 80 octets, ce qui est bien ce qui est spécifié dans le fichier.
On trouve enfin la résolution de l’image en pixels par mètre : 2e23 autant horizontalement que verticalement. Notez ici que la valeur hexadécimale se lit à l’envers. On trouve en effet dans le fichier 23 2e 00 00. Comme 2e23 vaut en décimal 11’811, cela signifie que la résolution est de 11’811 pixels/mètre. Comme un pouce vaut 2,54 cm, soit 0,0254 m, on a 11’811·0,0254 = 300 pixel/pouce = 300 pixel/inch = 300 dot per inch ou 300 dpi.
Les huit derniers octets concernent un éventuelle palette de couleur. Comme elle n’est pas présente ici, nous ne la détaillerons pas.
Partie image
Comme nous l’avons vu, la taille de l’image est de 80 octets, dont 5 octets fictifs pour que le nombre d’octets par ligne soit un multiple de 4. Afin de bien voir l’image, nous allons donc imposer une ligne de 16 octets en commençant juste après le 54e octet, soit 36 en hexadécimal. De plus, on va imposer un groupement par trois octets, correspondant à un pixel. On écrira ainsi :
xxd -g 3 -s 0x36 -c 16 image.bmp
Le résultat est alors le suivant :
L’image elle-même
La structure des octets de cette image est très intéressante. En effet, on voit que chaque ligne est composée de 5 fois trois octets qui correspondent à chaque pixel de l’image et à la fin de ligne d’un octet supplémentaire nul permettant d’avoir un nombre d’octets par ligne (16) qui soit un multiple de 4.
On voit aussi que tous les pixels entourant l’image sont nuls (000000). Ils correspondent à la bordure noire de l’image créée avec Gimp.
Reste les pixels centraux. Pour déterminer la couleur de ceux-ci, il faut relire la fin de la spécification de la structure de l’image. On y voit que les couleurs sont spécifiées dans l’ordre BVR et non RVB. Ainsi le second et le troisième pixel de la ligne 46 (00FF00) sont du vert, alors que le quatrième est du blanc. Tous les pixels centraux (2e, 3e et 4e) des lignes 56 et 66 sont du rouge. On pourrait en déduire que l’image est constituée de haut en bas, excepté sa bordure noire, d’un tiers de ligne verte, suivie d’un pixel blanc, puis de deux lignes rouges. Or, on sait que ce n’est pas le cas. En réalité, l’image se lit à l’envers : les lignes du haut, qui se lisent bien de gauche au droite, sont en fait celles du bas. L’image se lit donc en commençant par le pixel en bas à gauche, vers la droite et en montant.
Conclusion
L’analyse de l’image crée avec Gimp à l’aide d’un éditeur hexadécimal révèle que, moyennant la connaissance de la structure hexadécimale d’une image BMP, il est relativement simple d’en obtenir les spécifications et la forme directement en hexadécimal.